public class ItcastUDF extends UDF { public Text evaluate(final Text s) { if (null == s) { return null; } //返回大写字母 return new Text(s.toString().toUpperCase()); }}
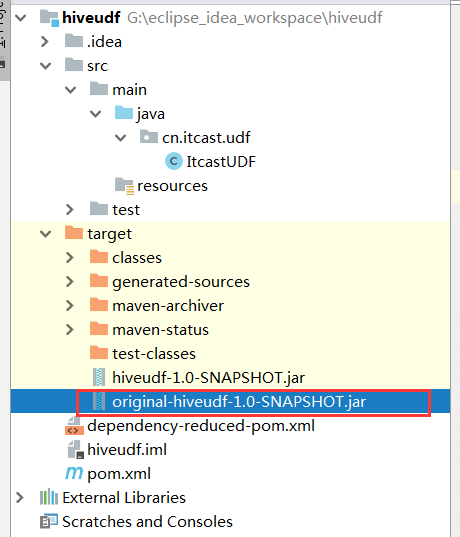
第三步:将我们的项目打包,并上传到hive的lib目录下
第四步:添加我们的jar包
重命名我们的jar包名称
cd /export/servers/hive-1.1.0-cdh5.14.0/libmv original-day_06_hive_udf-1.0-SNAPSHOT.jar udf.jar
hive的客户端添加我们的jar包
add jar /export/servers/hive-1.1.0-cdh5.14.0/lib/udf.jar;
第五步:设置函数与我们的自定义函数关联
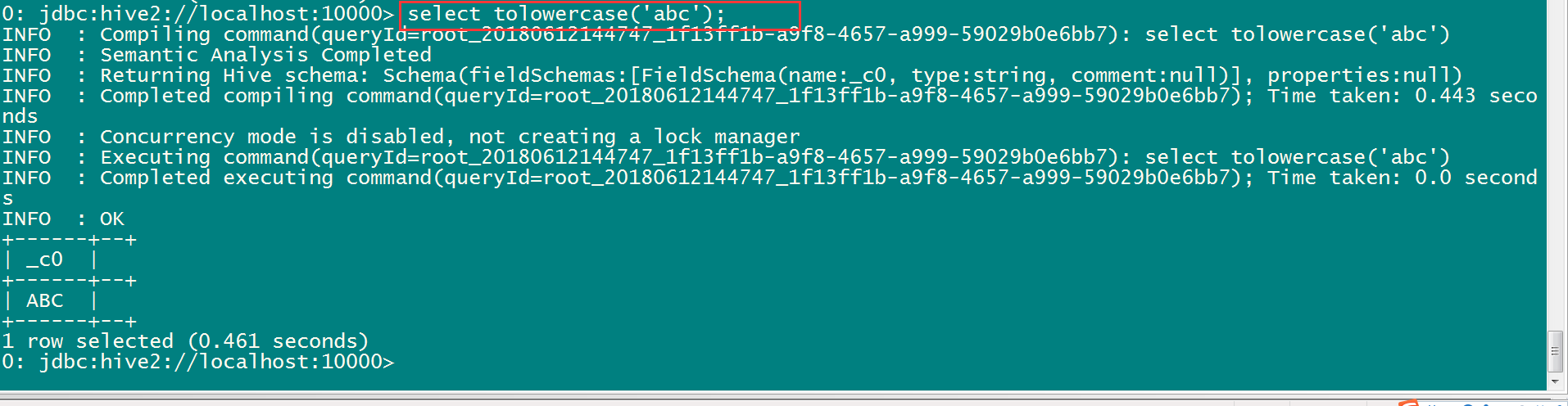
create temporary function tolowercase as 'cn.itcast.udf.ItcastUDF';